并查集学习笔记
定义
概念很重要,算法的核心就在于思想,而代码以及模板都是为了缩短解决问题的时间的手段,对于复杂问题来说,模板几乎没用。
言归正传,在计算机科学中,并查集是一种树型的数据结构,用于处理一些没有交集的集合(Disjoint Sets,一系列没有重复元素的集合)的合并及查询问题。对于每个集合,逻辑上都是一棵树,所有的操作都是基于树这个结构进行的。
并查集中主要有两种操作,即查询以及合并操作。
查询(Find):给定一个节点x,找出该点的所在树的根节点root(注意不是x的父节点,查询操作主要用于判断两个节点x与y是否属于同一颗树上,所以只需要两个节点所在树的根节点就行);也可以说是确定给定的元素属于哪一个子集。
合并(Union):将两颗树合并为一棵树;也可以说将两个集合合并为一个集合。
代码模板及解释
此处的代码模板也只是适用于解决大多数问题的核心代码,理解核心代码,可以提高写并查集代码的速度。
初始化
1 | int[] fa;// 节点对应索引值,fa[i]表示节点i的根节点 |
查询
原始版本
1 | /** |
优化版本(称为“路径压缩”)
1 | /** |
上述两种版本代码可以用一个树进行理解:
现有一颗树,树的节点为0,1,2,3,4,5,此时根节点为0,如图
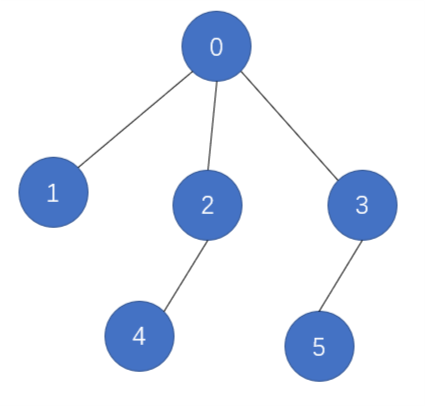
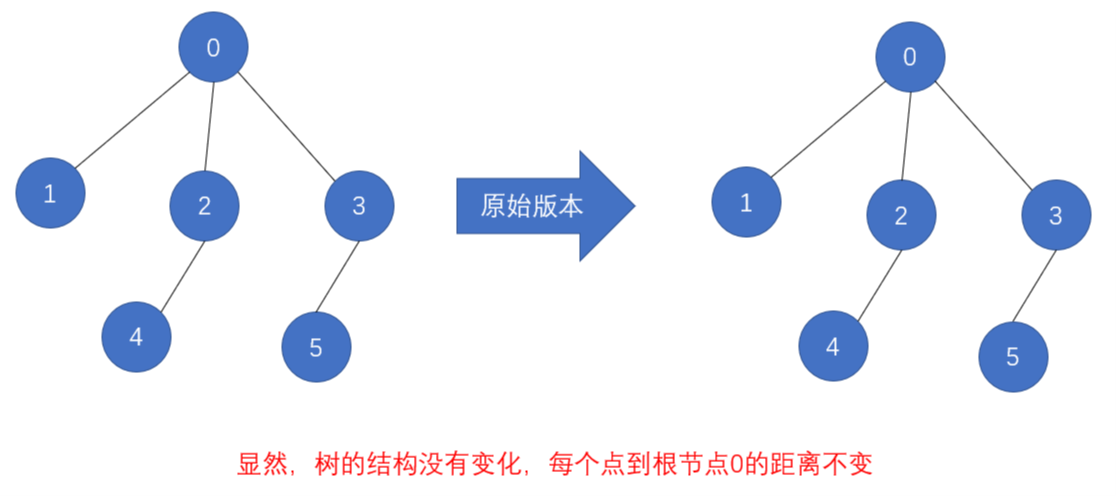
原始版本下查询后的结果如下:
优化版本下查询后的结果如下:
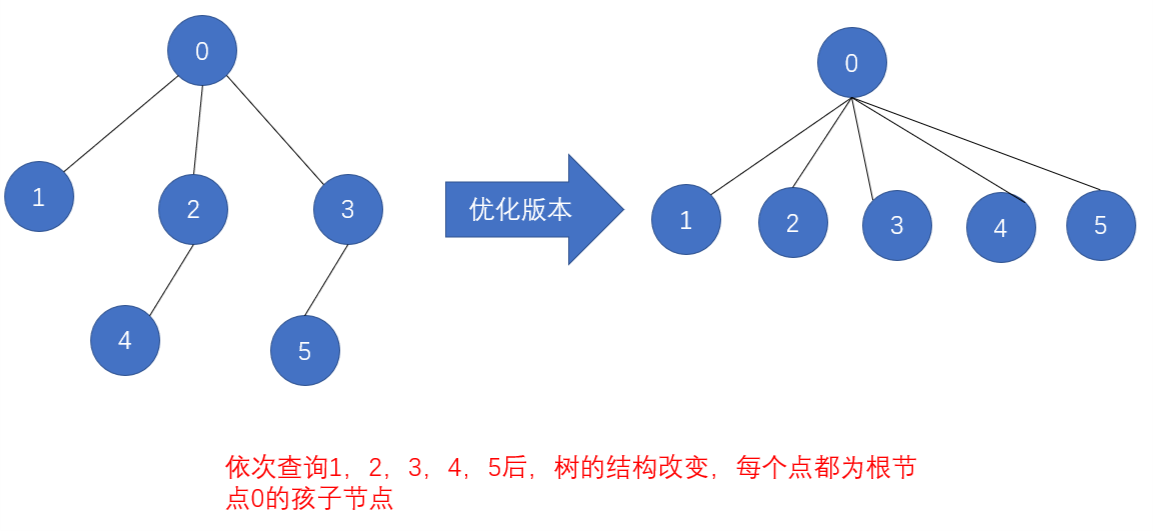
从上述两图,就可以看出,优化版本会减少下一次查询同一个节点的根节点的递归深度,减少比较次数。
合并
原始版本
1 | /** |
优化版本
1 | /** |
再次举一个例子,就个图看会很容易理解,
现有两棵树:
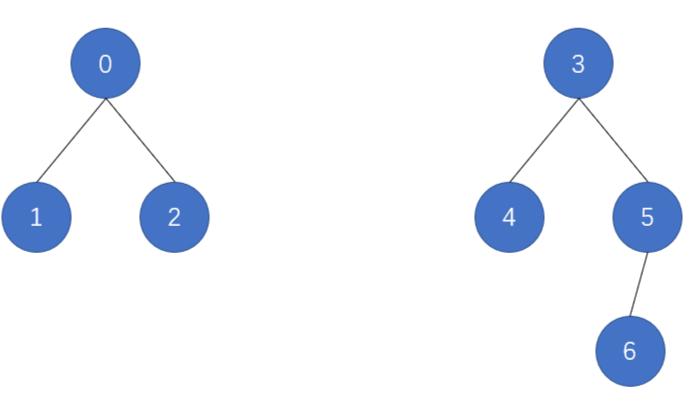
原始版本
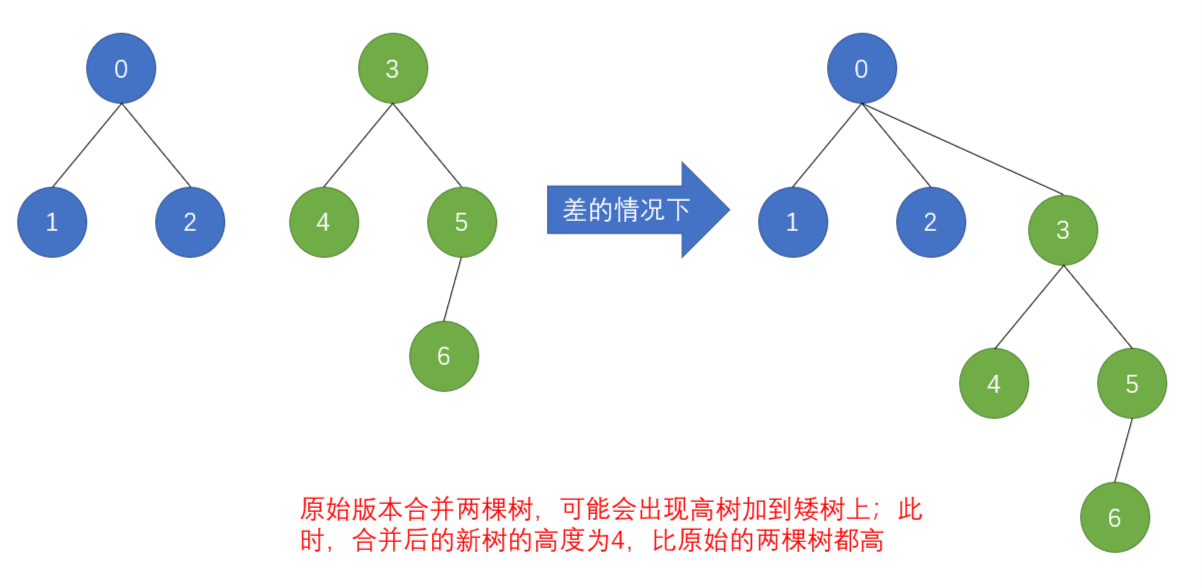
优化版本
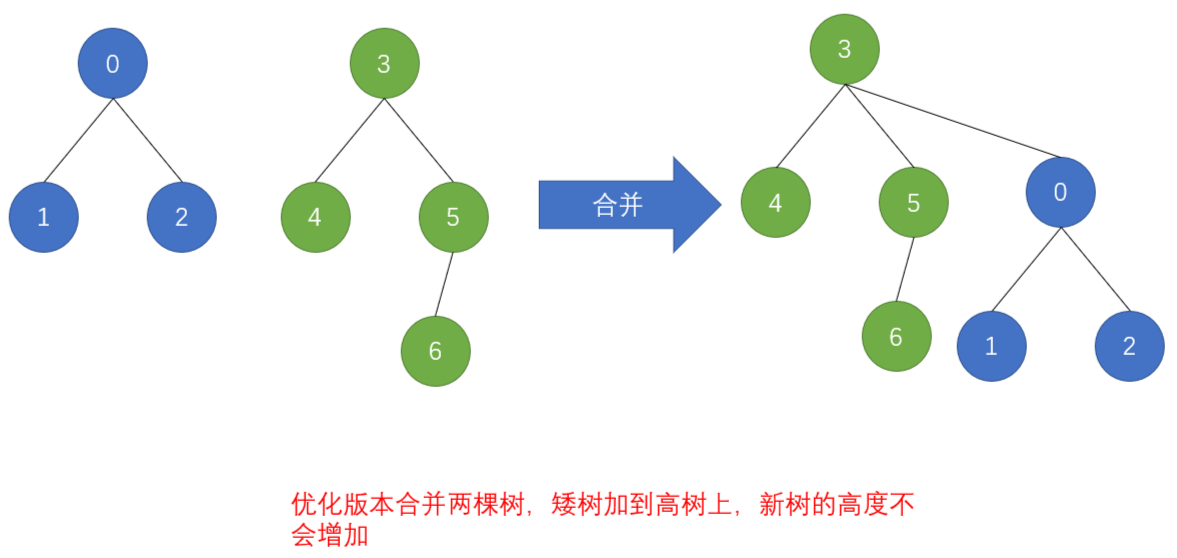
由上述两图可以看出,原始版本合并的新树的高度可能会增加,而优化版本的新树不会增加。树的高度直接影响之后的查询操作的时间复杂度。
应用场景
并查集可以解决的问题,一般DFS、BFS也可以解决,只不过时间复杂度高些。以下是可以使用并查集的场景:
- 可以判断两个节点是否在同一个树中,也可以说判断两个节点是否在同一个连通子图中。(一个树也是一个连通图)
- 统计极大连通子图的个数,即统计共有几个不同的根节点
- 形成最小生成树(Kruskal算法)
- 判断是否形成环,当两个节点的根节点都是同一个节点时,此时,形成了一个环
时间、空间复杂度
空间复杂度:因为要存储所有节点的索引,若节点数为n,则空间复杂度为O(n)
时间复杂度:这个没整明白O.O
趁热打铁
在力扣题库,按标签选择并查集,就可以看到所有并查集相关的题目了。
参考资料
维基百科:https://zh.wikipedia.org/wiki/%E5%B9%B6%E6%9F%A5%E9%9B%86
OI Wiki: https://oi-wiki.org/ds/dsu/v