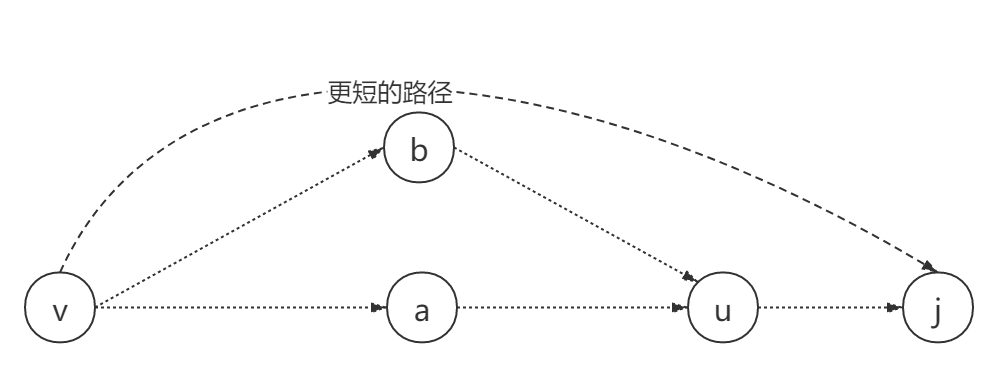
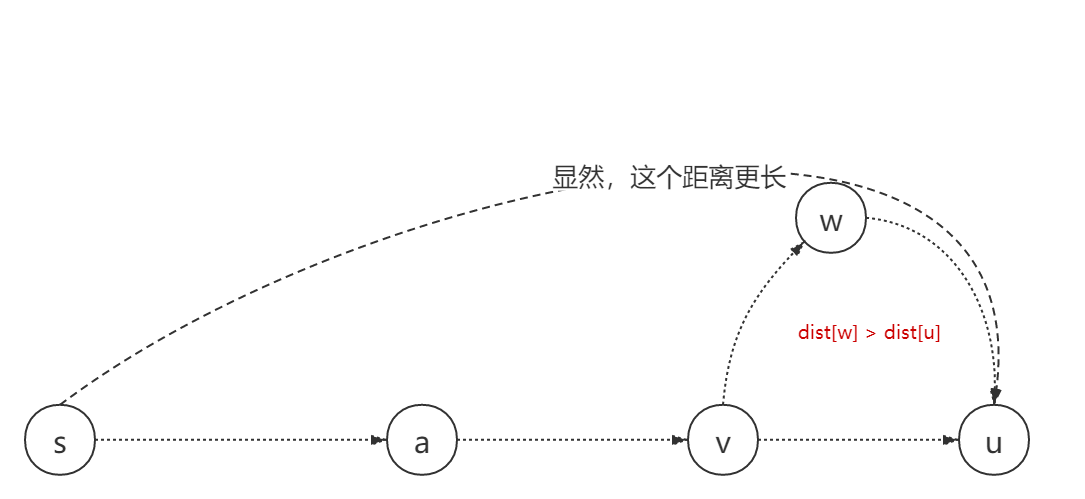
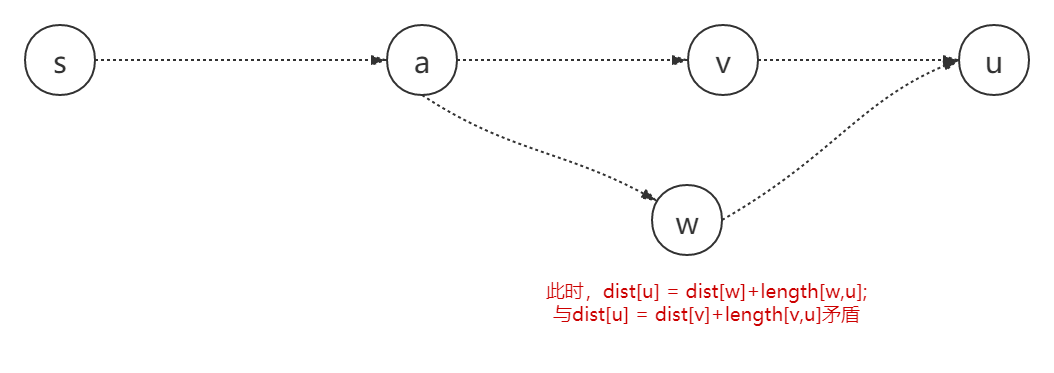
/** * floyd 最短路径 * @param n 顶点数 * @param edges 边 * @return 二维数组 表示每对顶点的最短路径 */ publicint[][] shortestPath(int n,int[][] edges) { int[][] dp = newint[n][n]; // 初始化 for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { if (i == j) dp[i][j] = 0; else dp[i][j] = Integer.MAX_VALUE; } } // 赋值 for (int i = 0; i < edges.length; i++) { dp[edges[i][0]][edges[i][1]] = edges[i][2]; }
// 三重循环 int k = 0; for (;k < n;k++) { for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { if (i == j || dp[i][k] == Integer.MAX_VALUE || dp[k][j] == Integer.MAX_VALUE) continue; dp[i][j] = Math.min(dp[i][j],dp[i][k]+dp[k][j]); } } } return dp; }
publicstaticvoidmain(String[] args){ Floyd h = new Floyd(); // 测试 int n = 7; int[][] edges = {{0,1,4},{0,2,6},{0,3,6},{1,2,1},{1,4,7},{2,4,6},{2,5,4},{3,2,2},{3,5,5},{4,6,6},{5,4,1},{5,6,8}};
int[][] ans = h.shortestPath(n,edges);
for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { if (ans[i][j] == Integer.MAX_VALUE) System.out.print("∞ "); else System.out.print(ans[i][j]+" "); } System.out.println(); } System.out.println(); } }